

Version control systems have revolutionized the way software teams manage their projects. These systems record a rich project history containing information about who made commits and when, how many files were modified, and in some cases when the conflicts occur. Developers and managers may study patterns of information contained in this history to understand why a piece of code evolved, to keep up with changes to pieces of code that interest them, or to find and debug faults.
The most widely used version control system in the world is Git VCS. Git was invented by Linus Torvalds to support the development of the Linux kernel, but it has since proven valuable to a wide range of projects. Worldwide, vast numbers of start-ups, collectives, and multinationals, including Google and Microsoft, use Git to maintain the source code of their software projects. Some host their own Git projects, and others use Git via commercial hosting companies such as GitHub, Bitbucket, and GitLab. The largest of these, GitHub, has over 73 million registered developers and was acquired by Microsoft in 2018.
The best indication of Git’s market dominance is a survey of developers by Stack Overflow. The survey found that 88.4% of 74,298 respondents in 2018 used Git (up from 69.3% in 2015), and the number of developers using other major VCSs has decreased.
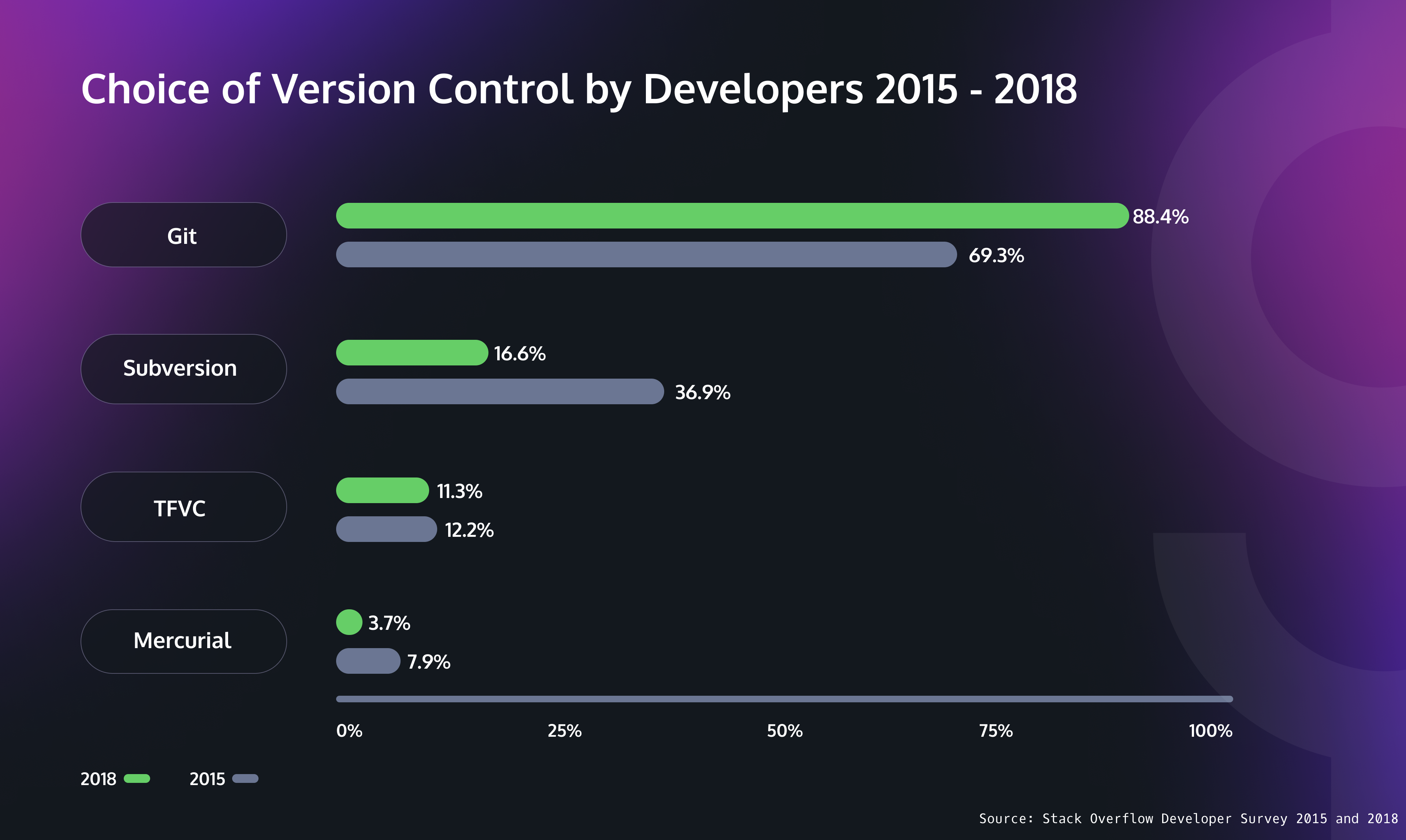
In fact, so dominant has Git become that the data scientists at Stack Overflow didn’t bother to ask the question in their 2019 and later surveys.
However, Git has not always been this ubiquitous. Let’s take a look at its ascent into mass popularity.
- - -
Early History
Necessity is the mother of invention. Git, the most popular Version Control System globally, was also born due to one such necessity.
The Linux kernel is an open source software project of a fairly large scope. During the early years of the Linux kernel maintenance (1991–2002), changes to the software were passed around as patches and archived files.
Linus Torvalds said in an interview that he never nearly wanted to do source control management. Initially, he hated all SCMs with passion until BitKeeper(BK) came along and changed how he viewed source control. He was pretty happy with BitKeeper having a local copy of the repository and distributed merging. Distributed source control solved one of Torvalds’s main issues with SCMs, i.e., the politics around “who can make changes.” BitKeeper showed that you could avoid this problem by giving everyone their own source repository. But BitKeeper also had its own set of technical problems, including its biggest downside: it wasn’t open source. BitKeeper was a proprietary and paid-for tool at the time, but the Linux development crew was allowed to use it for free. Due to this, many of the developers of the Linux kernel did not want to use it.
But since the open source alternatives did not meet the needs of the Linux Kernel Community, they had to settle with Bitkeeper. The situation lasted for three years and might have continued far longer if not for the breakdown of the relationship between the Linux Kernel Community and the commercial company that developed BitKeeper.
In early 2005, Larry McVoy, the copyright holder of BitKeeper, announced the revocation of a license allowing free use of the BitKeeper software. He claimed that Andrew Tridgell, an Australian computer programmer who was creating software that interoperated with BitKeeper, had reverse-engineered BitKeeper’s source code and violated its license. Many Linux core developers that relied on BitKeeper’s free software to develop the Linux kernel were now locked out from using it. Suddenly, BitKeeper could no longer be used for kernel development. The entire development toolchain, and all the developer culture that had sprung up around distributed version control, was thrown into uncertainty.
At this point, when everyone was wondering what Linus Torvalds would do next, something remarkable occurred. For the first time since its inception in 1991, Linus stopped work entirely on the Linux kernel. Since none of the existing free tools could do what he needed, Linus decided to write his own.

Linus Torvalds(Image Source, Credit: Krd, CC BY-SA 3.0, via Wikimedia Commons)
The Birth of Git
Setting out to provide the team with an alternative to BitKeeper, Torvalds outlined certain design criteria for the new version control system. He wanted to maintain the benefits that BitKeeper afforded the team as well as develop some improvements.

Torvalds coded in seclusion for a brief time, then shared his new conception with the world. Within days of beginning the project in June of 2005, Torvalds’ git revision control system had become fully self-hosting. Within weeks, it was ready to host Linux kernel development. Within a couple of months, it reached full functionality. At this point, Torvalds turned the project’s maintainership over to its most enthusiastic contributor, Junio C. Hamano, and returned full-time to Linux development once again.
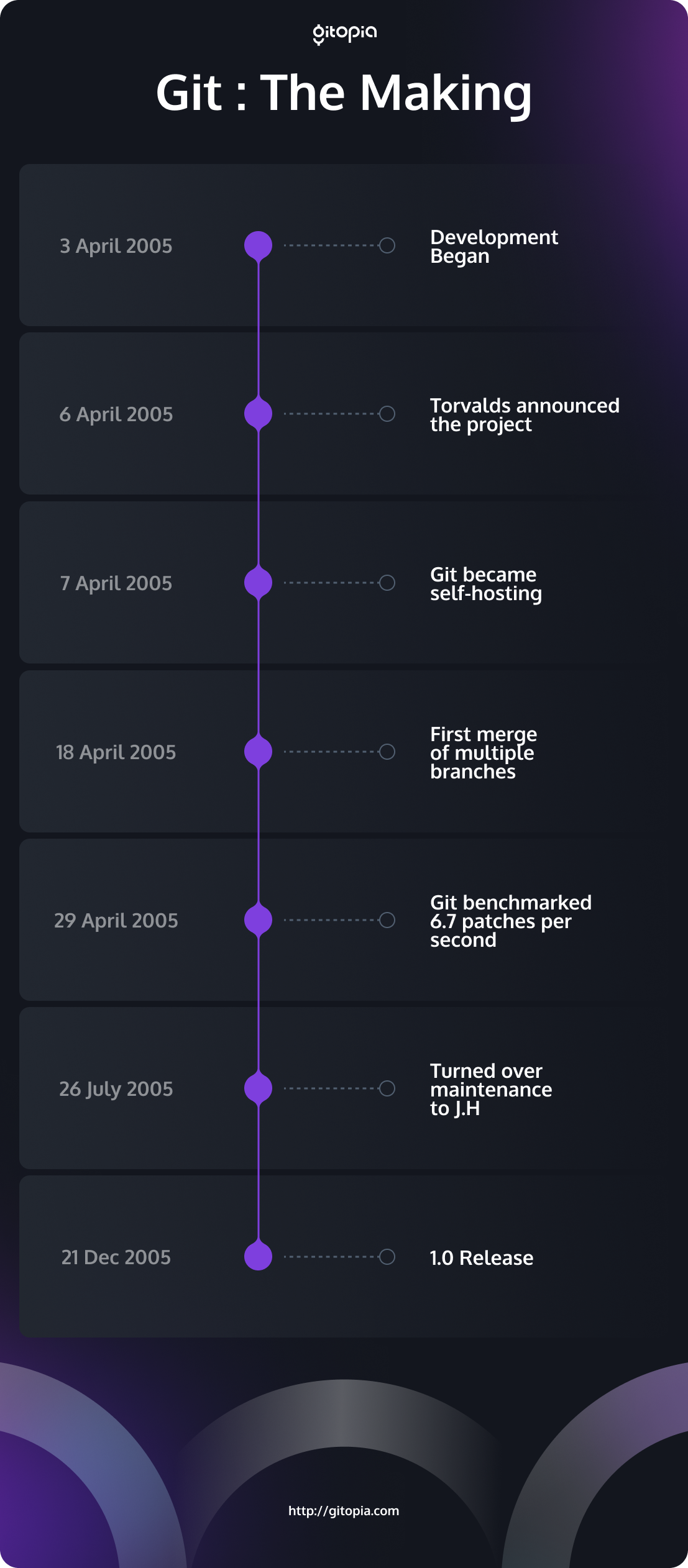
Timeline Showing Git’s Initial Development Phases
A stunned community of free software developers struggled to understand this bizarre creation. It did not resemble any other attempts at revision control software. In fact, it seemed more like a bunch of low-level filesystem operations than a revision control system. And instead of storing patches as other systems did, it stored whole versions of each changed file. How could this possibly be good? On the other hand, it could handle forks and merges with lightning speed and rapidly generate patches on demand.
Gradually, Junio drew together a set of higher-level commands that more closely resembled those of tools like CVS and Subversion. If the original set of git commands were the “plumbing,” this new set of commands was the “porcelain.” And, so they came to be called.
As much as there had been controversy and resentment over BitKeeper, there was enthusiasm and participation in the further development of Git. Ports, extensions, and websites popped up all over the place. Within a few years, pretty much everyone used Git. Like Linux, it had taken over the world.
Git: Becoming the De Facto Standard
![]()
Git Logo(Image Source, Credit: Jason Long, Image licensed under the CC BY 3.0)
When Git was first released, it was a bit strange to many Linux developers. It was touted as the source code control system of choice but did not resemble any of the most popular source control systems at that time. In particular, it looked different for one key aspect. Instead of storing the delta between old and new versions of the same file (aka, patches), Git stored all the revisions (not just the deltas) of files in a repository.
Such an unusual approach was strictly functional to the Torvalds’ primary goal: keeping it blazingly fast! Git can handle forks, merges, and generate patches quite quickly because of this. The original operations that Torvalds devised were too file-oriented and low-level, but Hamano has abstracted them away over time. The result is Git as we know it today - the de facto standard distributed version control system for tracking changes in source code.
Git is unique among version control systems in that each directory on every computer is a repository with its own history of changes. This means that developers can locally host a full-fledged version control system that works independently of network access but can optionally sync to a remote repository.
The exciting design and features of Git attracted developers to it. As it grew in popularity, some Cloud players could have developed their own VCS with a similar design, but instead, they each decided to use the prevailing standard. Despite not being a newbie-friendly tool, the ecosystem around Git that helped ease the learning curve helped developers become used to it and led to Git becoming the de facto standard.
Git’s success would not have been so massive without its commercial offshoots and hosting services: GitHub, Bitbucket, and GitLab. Using Git on the command line may suit the student or geek. Still, when it comes to establishing Git as an enterprise standard in a company, it is far safer to opt for a richer Web interface and all the necessary security aspects, such as integration with an organization’s single-sign-on solutions. Also, the network effects surrounding the popularity of Git ensure that it remains the de facto standard.
Today thousands of projects use Git, which has ushered in a new level of social coding among programmers.
- - -
Important Features of Git
1. Distributed System:
One of Git’s great features is that it is distributed. Distributed means that instead of switching the project to another machine, we can create a “clone” of the entire repository. Also, instead of just having one central repository that you send changes to, every user has their own repository that contains the entire commit history of the project. We do not need to connect to the remote repository; the change is just stored on our local repository. If necessary, we can push these changes to a remote repository.
Having a distributed system, Git allows the users to work simultaneously on the same project without interfering with others’ work. When a particular user gets done with their part of the code, they push the changes to the repository. These changes get updated in the local copy of every other remote user when they pull the latest copy of the project.
2. Compatibility:
Git is compatible with all the operating systems being used these days. It can also access the repositories of other Version Control Systems like SVN, CVK, etc. So, the users who were not using Git in the first place can also switch to Git without copying their files from the repositories of other VCSs into Git-VCS. Git can also access the central repositories of other VCSs. Hence, one can perform work on Git-SVN and use the same central repository.
3. Non-linear Development:
Git allows users from all over the world to perform operations on a project remotely. A user can pick up any part of the project, do the required operation, and then update the project. This can be done because of the Non-linear development behavior of Git. Git supports rapid branching and merging and includes specific tools for visualizing and navigating a non-linear development history. A major assumption in Git is that a change will be merged more often than it is written.
4. Branching:
In Git, a branch is a version of the repository that diverges from the main working project. Branches in Git provide a feature to make changes in the project without affecting the original version. By convention, the master/main branch of a git repository should contain the production-ready code. Well-tested and stable code lies here. Any new feature can be tested and worked upon on the other branches, and further, it can be merged with the master/main branch.
5. Lower Space Requirement:
Git stores all the data from the central repository onto local machines while cloning. This is important because many people are working on the same project, so the data in the central repository might be quite huge. One might worry that cloning that much data into local machines might take too long or result in system failure, but Git has already addressed such a problem. Git follows the criteria of lossless compression that compresses the data and stores it in the local repository occupying very minimal space. Whenever there is a need for this data, it follows the reverse technique and saves a lot of memory space.
6. Performance:
Git performs very strongly and reliably when compared to other version control systems. Committing new changes, branching, merging, and comparing past versions in Git are all optimized for performance. The algorithms used in developing Git take full advantage of deep knowledge about common attributes of real source code file trees, how they are usually modified over time and what the access patterns are. Git primarily focuses on the file content rather than file names while determining the storage and file version history. Object formats of Git repository files use several combinations of delta encoding and compression techniques to store metadata objects and directory contents. All this results in the efficient handling of large projects.
7. Open Source:
Git is released under the GNU General Public License version 2.0, an open source license. It is a widely supported open source project with over ten years of operational history. People maintaining the project release staged upgrades regularly to improve functionality and usability. The quality of open source software made available on Git is scrutinized countless times, and businesses today depend heavily on Git code quality.
8. Reliable:
In Git, the data of the “central” repository is always backed up in every collaborator’s local repository as the repository is being cloned each time a user performs the Pull operation. Hence, in the event of crashing the central server, the data will never be lost as it can be regained easily from any developer’s local machines. Once the Central Server is all repaired, the data can be retrieved by any of the multiple collaborators.
There is also a very low probability that the data is unavailable to any developer because the one who worked on the project last will have the latest version on its local machine. The same is the case at the client’s end. Suppose a developer loses its data because of some technical fault or unforeseen reasons. In that case, they can easily pull the data from the Central repository and get the latest version of the same on their local machine. Hence, pushing data to the central repository makes Git more reliable to work on.
9. Secure:
Git is secure. It uses the SHA1 (Secure Hash Function) to name and identify objects within its repository. Files and commits are checked and retrieved by its checksum at the time of checkout. It stores its history in such a way that the ID of particular commits depends upon the complete development history leading up to that commit. Once it is published, one cannot make changes to its old version.
Recently Git 2.29 was released with Experimental Support For using a more Secure SHA-256.
10. Extensible:
Git can be extended easily to support new features. For example, when you want to work with remote repositories that Git does not natively support, you can write your own custom remote helper, and Git will invoke it automatically when it works with these kinds of remotes. (read more)
e.g., Gitopia has a git remote helper for users to work with Gitopia remotes. End users just need to install this once and don’t have to do anything else. (read more)
These features have made Git the most reliable and highly used Version Control System of all time.
- - -
Future of Git
Being open source software, Git has a community of open source developers working tirelessly to fix bugs, add new features, and keep its dominance over other Version Control Systems in the market.
The major update to Git in recent times has been the addition of experimental SHA-256 support.
Git was engineered almost perfectly to fit the needs that Linus Torvalds and the Linux team sought. It met every core requirement for a VCS that Torvalds outlined and did so elegantly and simply to be as efficient as possible when being used. While there are some minor issues, Git is engineered quite well and will continue to be the VCS of choice for many years to come.
Moving from SHA1 to SHA256
At its core, the Git version control system is a content-addressable filesystem. It uses the SHA-1 hash function to name content. For example, files, directories, and revisions are referred to by hash values, unlike in other traditional version control systems where files or versions are referred to via sequential numbers. The use of a hash function to address its content delivers a few advantages:
- Integrity checking is easy.
- The lookup of objects is fast.
Over time some flaws in SHA-1 have been discovered by security researchers. On 23 February 2017, the SHAttered attack demonstrated a practical SHA-1 hash collision.
Git v2.13.0 and later subsequently moved to a hardened SHA-1 implementation by default, which isn’t vulnerable to the SHAttered attack, but SHA-1 is still weak. Thus it’s considered prudent to move past any variant of SHA-1 to a new collision-resistant hash. In late 2018 the project picked SHA-256 as its successor hash.
Git v2.29 includes experimental support for writing your repository’s objects using an SHA-256 hash of their contents instead of using SHA-1. With Git v2.29, Git can operate in full SHA-1 or full SHA-256 mode, but this means there is no interoperability between SHA-1 and SHA-256 repositories.
In future releases, Git will support interoperating between repositories with different object formats by computing both an SHA-1 and SHA-256 hash of each object it writes and storing a translation table between them. This will eventually allow repositories that store their objects using SHA-256 to interact with (sufficiently up-to-date) SHA-1 clients and vice-versa. It will also allow converted SHA-256 repositories to have their references to older SHA-1 commits still function as normal.
- - -
Git Hosting Services - Taking Git Mainstream
Git is cool, but it has a steep learning curve. To collaborate on git projects with other developers, you need to be able to manage remote repositories. A remote repository is, at its core, another instance of the repository you’re working in that is linked so that changes made to one can be pushed to the other. In a typical Git project, there is one remote repository known as the “Central” repository.
The central repo is almost always hosted either on a private server setup for this explicit purpose or on a git hosting service. But creating your own Git server is fairly complex and hard to do for average users. This was a significant barrier to ease of use. Another thing missing with Git was a modern web interface that made hosting Git repositories and fostering collaboration easier. Git also made this possible but did not make it easy. Thus came the need for Git hosting services.
So in 2007, GitHub came along and set up an easy-to-use website where developers could host and even manage their software projects using Git. GitHub offers almost all of the distributed version control and source code management (SCM) functionality of Git and adds its own features for code review, project management, integrations with other developer tools, team management, and documentation.
GitHub helped to take Git mainstream by making it easier to use and spreading the word beyond the Linux fraternity. The adoption of GitHub quickly grew, and it has become the most widely used git hosting service in the world today. The popular alternatives to GitHub with similar features are GitLab And Bitbucket.
“I’m just happy that it made it so easy to start a new project. Project hosting used to be painful, and with Git and GitHub it’s just so trivial to do a random small project. It doesn’t matter what the project is; what matters is that you can do it.”
-Linus Torvalds
Problems with Existing Git Hosting Services
Recently many problems and limitations have started popping up with the use of Centralized code hosting and collaboration platforms like GitHub.
A significant cause of worry is that due to the popularity of services like GitHub, most open source projects, including the popular decentralized projects, are hosted on them. But since corporations own GitHub and other similar centralized services, it makes critical open source development vulnerable to the policies and needs of these corporations.
Many other problems like being vulnerable to censorship, DMCA strike downs, unexpected outages of services, and lack of transparency in platform code and policies, have encouraged many developers to start looking at alternative git hosting services to host their repositories.
- - -
Gitopia is a next-generation Decentralized collaboration platform fueled by a decentralized network and interactive token economy that addresses the above-mentioned concerns and limitations of existing platforms. Gitopia stores git repositories on a blockchain network that is highly accessible, censorship-resistant, and empowers communities to create, own and contribute their open source code through open source incentivization.
Gitopia gives users the missing flows from conventional collaboration platforms, such as governance, proposals, and native bounties, while also working towards making open source licenses actionable.

Try out Gitopia: https://gitopia.com/home.
With Git and the power of blockchain, Gitopia ensures permanent storage for every single version of code ever created by the developers.
- - -
Follow us
Website: https://gitopia.com/
Whitepaper: https://gitopia.com/whitepaper.pdf
Telegram: https://t.me/Gitopia
Discord: https://discord.com/invite/mVpQVW3vKE
Twitter: https://twitter.com/gitopiaDAO
Forum: https://forum.gitopia.com/


{kind=link}
{kind=link}