

Yes, you read that right. Git, the most widely used version control system in the world today, is called a stupid content tracker! In the official Git website, under its documentation, Git is referenced as “Git- the stupid content tracker”. Apparently, Linus Torvalds, the developer of Git, thought it to be funny and unique. Through this article, let’s understand the reasoning behind this.
What is Git?
Git is a free, open-source distributed version control system tool designed to track changes in computer files and coordinate work on those files among multiple people with speed and efficiency. It is primarily used for source code management in software development, but it can be used to keep track of changes in any set of files. Right now Git is one of the most widely used VCSs and it has become the de-facto standard of versioning, adopted by both open source as well as corporations in their development toolbelt.
Git is called a DVCS (Distributed Version Control System)due to having a distributed architecture. Rather than have only one single place for the full version history of the software as is common in once-popular version control systems like CVS or Subversion (also known as SVN), in Git, every developer’s working copy of the code is also a repository that can contain the full history of all changes.
A Brief History of Git
In April 2005, while working on the 2.6.12 version of the Linux operating system, Linus Torvalds was not pleased with the existing VCSs available in the market to help him manage his code (BitKeeper as the main one). So he decided that he needed to create his own VCS to keep track of changes in the Linux core. The design requirements were:
- Consider the Concurrent Versions System (CVS) as an example of what not to do. If in doubt, make the exact opposite decision
- High performance
- Support a distributed, BitKeeper-like workflow
- Include robust safeguards against corruption, either accidental or malicious
With these requirements, Git was created, a VCS very different from the ones in use at that time. Since then, it has been growing almost universally to manage version control and team contributions.
Naming of Git
The name ‘Git’ was given by Linus Torvalds when he wrote the very first version. Quoting Linus: “I’m an egotistical bastard, and I name all my projects after myself. First ‘Linux’, now ‘Git’”(‘Git’ is British slang for unpleasant person).
Alternatively, in Linus’s own words as the inventor of Git: “Git” can mean anything, depending on your mood:
- a random three-letter combination that is pronounceable, and not actually used by any common UNIX command. The fact that it is a mispronunciation of “get” may or may not be relevant.
- stupid. contemptible and despicable. simple. Take your pick from the dictionary of slang.
- “global information tracker”: you’re in a good mood, and it actually works for you. Angels sing, and a light suddenly fills the room.
- “goddamn idiotic truckload of sh*t”: when it breaks
Why is Git called ‘the stupid content tracker’?
It’s a reference to how Git internally represents things. Git started in the most basic, simple way possible. The earlier versions of Git were barely accessible, and it wasn’t really trying to be smart. Basically, it’s just a file system because, as Linus Torvalds explained, file systems are something he understands. Tools were built on top to make it more accessible for more people, and as such, it seems smarter, but it’s really not trying to be smarter than it should be. This is a good thing because it means that it is in our means to correct something that might go wrong and mostly understand its inner workings, which helps us to use the tools better.
The Git model is quite simple.
- A blob is a bunch of bytes that represent the content of a file at a point in time. It is important to note that it is the contents that are stored and tracked, not the files, their types, or filenames.
- A tree is a collection of blobs. Directories in Git basically correspond to trees.
- A commit is a reference to a tree that also contains a reference to one or more parent commits (and some metadata, like a date, an author’s name, some explanatory text, etc.)
- A tag is an object that provides a permanent shorthand name for a particular commit.
- The above are the four main object types in Git, the first three being the most important to really understand the main functions of Git. All of these types of objects are stored in the Git object database, which is kept in the Gitit directory, also known as a Git repository.
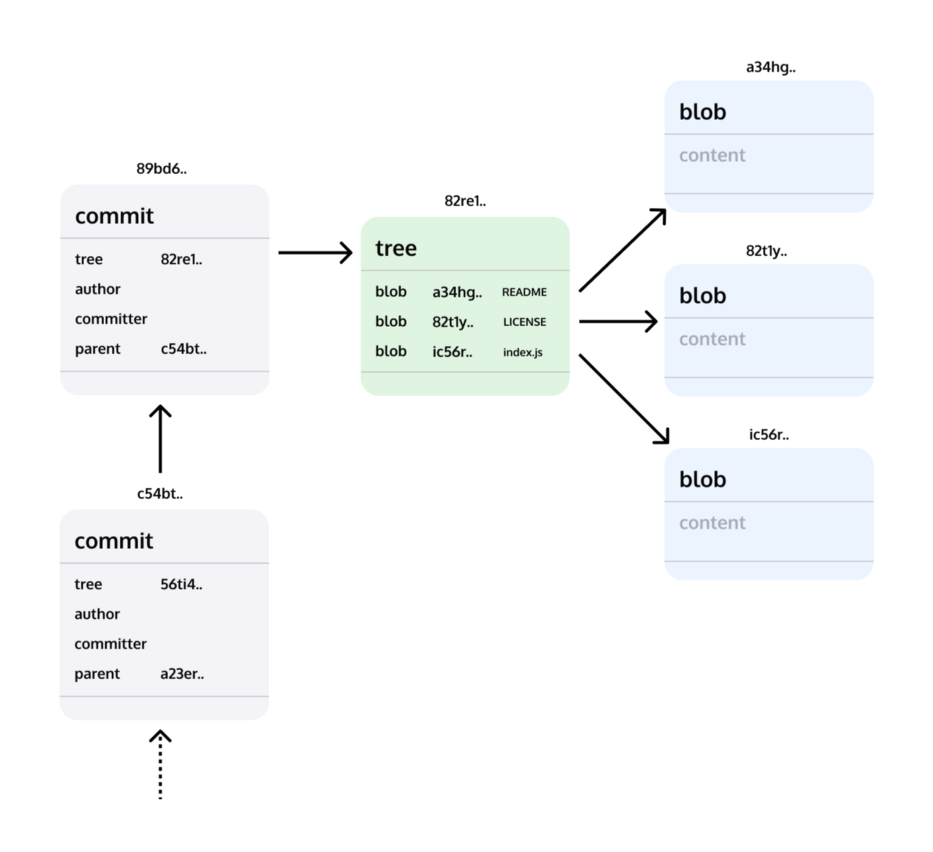
Git data model
That’s it. Notice there’s nothing about patches, diffs, lines added or removed, etc. From the Git conceptual model, each revision is a complete copy of the whole project.
Git is a stupid content tracker because it has no idea what’s inside those blobs, and it doesn’t try to store fine-grained information like “lines 235–250 added, lines 404–410 removed,” or anything like that. Git doesn’t know anything about the type of content you put in it. It does, however, give you the exact content you put in it back out.
Collaborating on Git projects
To collaborate on Git projects with other developers, you need to be able to manage remote repositories. A remote repository is, at its core, another instance of the repository you’re working in that is linked so that changes made to one can be pushed to the other. The remote repository could be hosted on a Git hosting service like GitHub or GitLab, it could be on a co-worker’s machine, or it could even be another folder on your local machine.
In a typical Git project, there is one remote repository known as the “Central” repository. The central repo is almost always hosted either on a private server setup for this explicit purpose or on a Git hosting service. Since creating your own Git server is fairly complex, most people rely on a Git hosting service to house their central repositories.
The most widely used Git hosting service in the world today is GitHub. GitHub offers all of the distributed version control and source code management (SCM) functionality of Git and adds on the top of it its own features for code review, project management, integrations with other developer tools, team management, and documentation. The other alternative Git hosting services like GitLab and BitBucket also have similar features.
However, these services are owned by corporations and carry many risks like vulnerable to censorship, single point of failure, lack of community say in policy-making, etc. These problems have encouraged many developers to start looking at alternative Git hosting services to host their repositories.
Gitopia is a decentralized Git hosting service with many added features to make collaboration on code easy and accessible. Gitopia proposes a system that stores Git repositories in a decentralized network, one that is highly accessible, censorship-resistant, and empowers communities to innovate, create and contribute open-source code.
Gitopia introduces Git version control to a wider audience. Gitopia, by using Git as its base for version control and collaboration, empowers its users to track the history of changes as people and communities collaborate on projects together. As the project evolves, the community can run tests, fix bugs, and contribute new code with the confidence that any version can be recovered at any time. Developers can review project history to find out:
- What changes were made?
- Who made the changes?
- When were the changes made?
- Why were the changes needed?
With Git and the power of blockchain, Gitopia ensures permanent storage for every single version of code ever created by the developers.
- - -
Follow us
Website: https://gitopia.com/
Whitepaper: https://gitopia.com/whitepaper.pdf
Telegram: https://t.me/Gitopia
Discord: https://discord.com/invite/mVpQVW3vKE
Twitter: https://twitter.com/gitopiaDAO

